Understanding Bias Part I
Accordingly, we use the term bias to refer to computer systems that systematically and unfairly discriminate against certain individuals or groups of individuals in favor of others.
Bias in Computer Systems - Friedman & Nissenbaum, 1996
What is so bad about algorithmic bias anyway? How has it affected the world? To figure out what algorithmic bias is, it can be useful to consider some real-world examples.
In this chapter, we take a look at what some consequences of algorithmic bias look like.
Two Types of Harms
AIS are increasingly used to help allocate resources. Credit scoring models that help banks filter loan applications “allocate” loans. Hiring models help companies to “allocate” jobs. Medical diagnosis models help to “allocate” appropriate treatment. The AIS in these examples help identify who to give what. We are affected by these systems because we are denied or given something as a result of an AIS decision.
On a more abstract level, AIS are also increasingly affecting the way we perceive or represent the world. Think Google Search, Facebook’s News Feed and YouTube’s Recommended feed. This is also known as “filtering”
We can classify the consequences of algorithmic bias in the same way. This was proposed by Kate Crawford in her NIPS 2017 keynote The Trouble with Bias
| Harms of Allocation | Harms of Representation |
|---|---|
| Immediate | Long term |
| Easily quantifiable | Difficult to formalize |
| Discrete | Diffuse |
| Transactional | Cultural |
Comparison between the two types of harm, from Crawford’s NIPS 2017 keynote

A framework proposed by Kate Crawford classifies algorithmic bias by the type of harm caused. Harms of allocation refers to unfairly assigned opportunities or resources due to algorithmic intervention. Harms of representation refers to algorithmically filtered depictions that are discriminatory.
Harms of Allocation

An allocative harm is when a system allocates or withholds certain groups an opportunity or a resource.
The Trouble with Bias, Kate Crawford at NIPS2017
Automated eligibility systems, ranking algorithms, and predictive risk models control which neighborhoods get policed, which families attain needed resources, who is short-listed for employment, and who is investigated for fraud.
Automating Inequality - Virginia Eubanks
Harms of allocation arise from the unjust distribution of opportunities and resources, such as jobs, loans, insurance and education. An allocative harm can range from a small but significant and systematic difference in treatment, all the way to complete denial of a particular service.
COMPAS
The Correctional Offender Management Profiling for Alternative Sanctions, or COMPAS, algorithm is probably the most infamous case study in algorithmic bias. In areas where COMPAS was used, defendants typically answer a COMPAS questionnaire when they are first booked in jail.
A past sample of a COMPAS questionnaire.
Using the responses, the COMPAS model outputs several scores related to recidivism. These include scores for Risk of Recidivism and Risk of Violent Recidivism, which go from 1 to 10, with 10 being highest risk. The scores were given to judges and they often had a huge influence on the sentence:
After Brennan’s testimony, Judge Babler reduced Zilly’s sentence, from two years in prison to 18 months. “Had I not had the COMPAS, I believe it would likely be that I would have given one year, six months,” the judge said at an appeals hearing on Nov. 14, 2013.
Machine Bias - Julia Angwin et al., 2016
If we think of COMPAS as a model for potentially “allocating” freedom, harms of allocation can become very severe. In ProPublica’s exposé on COMPAS, the journalists argued that the algorithm was “biased against blacks”.
In forecasting who would re-offend, the algorithm made mistakes with black and white defendants at roughly the same rate but in very different ways.
- The formula was particularly likely to falsely flag black defendants as future criminals, wrongly labeling them this way at almost twice the rate as white defendants.
- White defendants were mislabeled as low risk more often than black defendants.
In short, black defendants were more likely to be wrongly accused of reoffending, while white defendants were more likely to “escape detection”. We cited this example in an earlier section (The Impossibility Theorem), where we also mentioned that Propublica and Northpointe employed different definitions of fairness. Putting aside the debate of which definition of fairness to apply, there are also other considerations.
Proxy Labels
The term “recidivism” refers to the likelihood of a criminal committing another crime, after they have been convicted. To train a recidivism prediction model, the training data should ideally have labels denoting whether a convicted criminal has reoffended. But in reality, we don’t know when someone has committed a crime, only when someone has been arrested. So, we use a proxy. Instead of labels denoting whether a convicted criminal has reoffended, the labels denote whether a convicted criminal has been convicted again. That might be the closest we can get, but is it close enough?
Let’s think about some of the differences between “reoffending” and “being convicted again”.
- A criminal who has reoffended might not necessarily be caught. This means that we are missing out on the smart and lucky criminals who escape conviction.
- The system is imperfect. Unfortunately, innocent people sometimes get wrongly accused and wrongly convicted. This means that we could have people labeled “convicted again”, who have not actually “reoffended”.
Okay, now let’s go one step further and think about how a trait like race might affect these two differences. Racism in the police has been well-documented in literature
- If racism has a major influence on police practices like stop-and-frisk, we might find that white re-offenders have a higher chance of not getting caught, as compared to black re-offenders. This might cause our dataset to underestimate the number of white re-offenders.
- And likewise, we might find that black individuals are subject to wrongful arrests more frequently than white individuals. In that case, our dataset might be overestimating the number of black repeat offenders.
In other words, by using the proxy label of “being convicted again” rather than “reoffending”, we could be exaggerating the recidivism rate of black individuals and systematically biasing the dataset along racial lines. Obviously all of this is hypothetical and requires more substantial evidence. Nevertheless, when faced with problems like these, it might be prudent to ask if an algorithmic solution is really the answer.
Public Disclosure

Despite the important role that risk scores like COMPAS play in the criminal justice system, there is little public information about these systems.
[Researchers Sarah Desmarais and Jay Singh’s] analysis of [19 risk methodologies] through 2012 found that the tools “were moderate at best in terms of predictive validity,” Desmarais said in an interview. And she could not find any substantial set of studies conducted in the United States that examined whether risk scores were racially biased. “The data do not exist,” she said.
Machine Bias - Julia Angwin et al., 2016
Important information that probably should be available include:
- What goes into the risk score?
- How is it calculated?
- What is the accuracy?
- How is this accuracy measured?
- What definition of fairness was used to develop the scores?
- Why this definition instead of other definitions?
- What are potential fairness violations?
Not having to disclose such information allows bias to remain undetected. Because this information is missing, alternative actors such as ProPublica take up the mantle to evaluate these systems. But this often happens only after the AIS have been in use for some time and harm has been done.
Then again, a potential problem is that public disclosure might undermine the validity of the scores. Understanding how the risk scores are calculated might enable malicious individuals to game the scores. Nevertheless, considering what is at stake, we have to put some thought into how appropriate disclosure can be made about these scores.
The Greater Good

“‘Greater good?’ I am your wife! I’m the greatest good you’re ever gonna get!”
Honey Best, Frozone’s wife in The Incredibles
For the criminal justice system, we can think of its overarching aim as the greater good of promoting societal safety. The sentencing process can be seen as one of its major tools:
Four major goals are usually attributed to the sentencing process: retribution, rehabilitation, deterrence, and incapacitation.
Sentencing and Corrections in the 21st Century: Setting the Stage for the Future - Doris Layton Mackenzie, 2001
When we use a tool like COMPAS to decide the length of a prison sentence, we seem to focus on retribution and incapacitation, and neglecting rehabilitation. Is that really serving the greater good of societal safety? By reducing the issue of societal safety to recidivism prediction, we get a quantifiable problem that might be simpler to solve. But this neglects the greater objective and other alternative problems and solutions. We can see this as an instance of Selbst et al.’s Framing Trap, which we covered previously.
When we consider the greater objective of societal safety, alternative solutions might come to mind. Rather than using COMPAS for determining jailtimes, it can help design specific intervention and rehabilitation measures customized for each defendent. In fact, this might have been what COMPAS was designed for, which brings us to our next section.
Human-Algorithm Interaction
In the earlier quote from the article, we see how Judge James Babler from Barron County, Wisonsin, had been influenced by COMPAS to give a more severe sentence than he would have otherwise given. The more severe sentence was only retracted after Tim Brennan, Northpointe’s founder, had “testified that he didn’t design his software to be used in sentencing”. This is reflected in Chapter 4 of Northpointe’s Practitioner’s Guide to COMPAS Core, which lists different interventions for specific aspects. Throughout the chapter, there are repeated references to non-incarceration interventions. For example, under the Financial Problems section, we see the following recommendation:
Education on money management and fulfilling court ordered financial commitments is part of the necessary approach when considering interventions. Assuming someone knows how to manage their finances is an erroneous starting place, vocational training may also play a role in creating a successful change plan.
Practitioner’s Guide to COMPAS Core - Northpointe, 2015
So what went wrong?
Maybe Brennan had been too idealistic when thinking about how judges might be using COMPAS scores. Maybe Brennan didn’t think that the scores could be interpreted as a measure for how long someone should be jailed. Whatever it is, the ones who deployed COMPAS had not appropriately considered how it might be used and how it might influence others. Recall Selbst et al.’s Ripple Effect Trap mentioned earlier. Here we neglected the “ripple effects” that COMPAS had on judges and underestimated COMPAS’s potential for allocative harm. When we take these into consideration, we might have changed aspects of the system. For example, instead of risk scores, COMPAS could explicitly output the recommended intervention. That could reduce the chance of misunderstanding or misusing the risk scores.
COMPAS is a classic case of allocative harm in algorithmic bias literature, concerning the "allocation" of freedom. By examining the larger sociotechnical context of the criminal justice system that COMPAS is employed in, we identified many potential problems relating to algorithmic bias, such as:
- Differences between proxy labels and actual labels
- Public disclosure of fairness considerations
- Neglecting the larger objective
- Failing to comprehensively consider how the AIS affects the system
For more examples of allocative harms, check out Cathy O'Neil's Weapons of Math Destruction
Harms of Representation
[Representative harms] occur when systems reinforce the subordination of some groups along the lines of identity.
The Trouble with Bias, Kate Crawford at NIPS2017
If you control the flow of information in a society, you can influence its shared sense of right and wrong, fair and unfair, clean and unclean, seemly and unseemly, real and fake, true and false, known and unknown.
Future Politics - Jamie Susskind, 2018
Google Image Search
Most of us have had experience with Google Image search. Maybe it was to find some stock photos or wallpapers. Or maybe it was to look up what some exotic animal looked like. One thing we might have noticed is that the search results often return stereotypical images of our query. Searching “playground” would give us photos of the classic outdoor playground with small slides and steps. Searching “bedroom” would return photos of nicely made beds and tidy rooms that would seem perfectly natural in a furniture catalogue.
Latest Image Search for “playground”.
Latest Image Search for “bedroom”.

Such stereotypes go beyond objects and places, extending to queries of people as well. Studies have found that Google’s Image Search perpetuated and exaggerated gender and racial stereotypes for certain keywords, such as “CEO”, “doctor” and “nurse”
In April 2015, a Google Image search for the term “CEO” surfaced results that were manifestations of both racial and gender biases. An overwhelming majority of the images were photos of white males in suits. Since these biases have been flagged by several researchers, they appear to have been mitigated somewhat and a recent search shows a far more diverse result (see below).

Results from Google Image Search for “CEO” in April 2015 (retrieved from here

Results from Google Image Search for “CEO” in July 2019 show a more diverse distribution, in terms of race and gender.
Latest Google Image Search for “CEO”.
Harms of representation are dangerous because they shape how we see the world. And in turn, how we see the world shapes the world. A generation raised solely on fairy tales of damsels in distress might not recognize the existence of heroines and men in need of saving. A generation raised solely on image search results of white male CEOs may find it difficult to entertain the possibility of a non-male non-white CEO. By limiting our cognitive vocabulary, these harmful representations become additional psychological obstacles that must be overcome.
Furthermore, when these harmful representations manifest themselves as biased actions and decisions they become self-fulfilling prophecies. Fed on a diet of white male CEO images, non-male non-white individuals might never fight for the position and we may never encourage them to go for it. We might even discourage them from pursuing what seems like an unrealistic ambition. Over time, there are fewer and fewer non-white non-male CEOs and the biases embodied by the search results turn out to be an accurate prophecy.
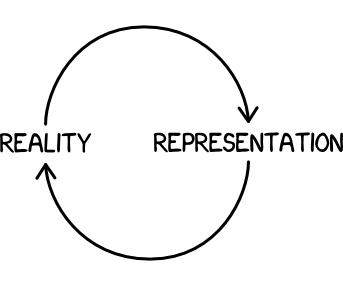
In that case, what does an unharmful representation look like? Two possible alternatives to consider are accurate representations and ideal representations.
Accurate Representations
Yes, the Google Image results in April 2015 were dominated by white males. But technically, in 2014, only 4% of the 500 companies on the US S&P 1500 had female CEOs
On the other hand, search results that have zero female images would be obviously inaccurate. Such results would be perpetuating false and exaggerated gender stereotypes.
Ideal Representations
In March 2015, the New York Times ran an article titled “Fewer Women Run Big Companies Than Men Named John”
Representations both embed and influence unwritten norms and values. Following the cycle between representation and reality, we can make the world a better place by first seeing it as a better place. In our example, the presence of more gender- and race-diverse search results for “CEO” can encourage non-white non-male candidates to go from minority to mainstream.
Accuracy versus Idealism
There is merit behind both an accurate representation and an ideal representation. But in an imperfect world, representations cannot be both accurate and ideal. Decisions and compromises have to be made about which is more important for the given application.
Imagine if a company’s internal personnel directory tries to give an ideal and fair representation of a query for the company’s regional managers. That would probably defeat the purpose of the directory. On the other hand, people often use Google to learn more about the world. Maybe presenting a more equal representation could eventually make the real world a more equal place. As always, making the right choice requires knowledge about the context.
Biased results in Google Image Search can be seen as an instance of representative harm. The harm caused is more subtle and indirect but no less dangerous than harms of allocation. A biased representation can influence people's behaviors and in turn, change the world for the worse.
Fixing harms of representation requires a conversation about the tradeoffs between an accurate representation and an ideal one. Once again, detecting such harms and fixing them requires thinking beyond the scope of mathematical algorithms and venturing into social implications.
For more interesting examples, check out the problems of bias in word embeddings